

Kann man einen Raspberry Pi als Plattform für Cloud Computing benutzen? Wir haben es einfach mal ausprobiert.
Da ich gerade mein Masterstudium “Informatik” anfange, habe ich mir überlegt, meinen Raspberry Pi 3 B mal wieder auszugraben, damit ich darauf verschiedene Anwendungen für meine Uni-Projekte laufen lassen kann. Für meine Projekte im Bachelorstudium habe ich zum Beispiel öfters mal einen Datenbankserver oder einen Webserver gebraucht, die ich damals schon auf dem RasPi betrieben habe.
In den letzten beiden Semestern und für meine Bachelorarbeit habe ich dafür Container-Virtualisierung mit Docker genutzt. Das hatte gegenüber dem normalen Betrieb direkt auf dem Betriebssystem des RasPi ein paar Vorteile:
- So konnte ich mir nicht mein Debian auf dem RasPi durch Änderungen an den installierten Paketen und an Konfigurationsdateien “kaputtbasteln”, da ich ja immer nur in den Containern arbeite.
- Mehrere Web- und Datenbankserver konnten unabhängig von einander verwaltet werden; die installierten Server-Plugins und die Server-Einstellungen konnten sich also nicht gegenseitig beeinflussen oder behindern.
- Besonders wichtig: Mit Docker konnte ich alle nötigen Dinge zur Bereitstellung der Server als Dateien verwalten. Ein Docker-Container wird anhand der Anweisungen aus einem Docker-Skript auf Basis eines Ausgangs-Systemimages gebaut. Ich musste also nur die notwendigen Pakete über das Skript mitinstallieren lassen, die bearbeiteten Konfigurationsdateien zusammen mit dem Softwareprojekt ablegen und alle benötigten Verzeichnisse und Dateien in den erstellten Container hineinlinken lassen. Dadurch wird sichergestellt, dass man beim Entwickeln der App die selbe Server-Konfiguration nutzt wie in der Produktivumgebung und, dass beim Ausrollen des Projekts auf einem neuen Rechner alles korrekt konfiguriert ist.
Was ist eigentlich CONTAINER-VIRTUALISIERUNG?
Container-Virtualisierung – oder kurz Containerisierung – ist eine spezielle Form der Betriebssystemvirtualisierung. Im Gegensatz zur herkömmlichen Virtualisierung läuft hier jedoch keine virtuelle Maschine mit einem kompletten eigenen Betriebssystem inklusive Betriebssystemkern parallel zum Host-Betriebssystem.
Stattdessen benutzt der Container den Betriebssystemkern des Hosts mit und erweitert diese Basis um eigene Bibliotheken und Anwendungen. Ein Ubuntu-Container verwendet so z.B. auf einem Debian-Host den Linux-Kernel des Hosts, aber die Ubuntu-Version der systemnahen Bibliotheken und die Standard-Paketauswahl von Ubuntu. Dadurch verhält sich der Container wie eine ganz normale Ubuntu-VM, benötigt aber viel weniger Rechenleistung und Ressourcen.
Obwohl die Container alle gemeinsam auf den Betriebssystem-Kernel zugreifen, werden die Container durch Kernelmechanismen voneinander getrennt. Die Container können weder andere Container noch das Host-Betriebssystem beeinflussen.
Bei Docker gibt es noch einen Spezialfall: Docker verwendet grundsätzlich einen Linux-Kernel. Auf Nicht-Linux-Hostsystemen läuft daher der Linux-Kernel in einer eignen, konventionellen VM, da das Hostbetriebssystem ja kein Linux ist. Die Container greifen dann auf den Kernel der VM zurück.
An dieser Stelle möchte ich ausdrücklich auf den BuzzZoom-Podcast von Dirk und Mario hinweisen, wo das Thema Containerisierung schon ausführlich besprochen wurde.
Die Sache mit Docker war schon ganz nett, hatte aber noch Optimierungspotential: Zum Beispiel verbraucht das als Unterbau verwendete Debian unnötig viele Ressourcen (Speicherplatz und RAM) und es liefen auch einige Dienste außerhalb der Containerisierung, z.B. Git. Außerdem wäre es ganz nett, eine grafische Oberfläche zur Überwachung und Verwaltung zu haben. Um das Ganze nun etwas zu optimieren und etwas vielseitiger zu gestalten, möchte ich auf dem Mini-Rechner ein möglichst kleines Linux laufen lassen, auf dem dann mit Container-Virtualisierung beliebige Anwendungen als Server laufen können.
Als Betriebssystem soll Alpine Linux zum Einsatz kommen, das deutlich weniger Speicher und CPU-Leistung benötigt als beispielsweise ein Ubuntu oder das Standard-Betriebssystem für den Raspberry Pi, Raspbian. Dadurch soll mehr Leistung für die Container zur Verfügung stehen.
Für die Container-Virtualisierung soll Kubernetes zum Einsatz kommen, die zur Zeit wohl beliebteste Software zur Bereitstellung und Verwaltung von Container-Anwendungen. Docker bietet keinen so großen Funktionsumfang zur Verwaltung von Containern wie Kubernetes, kann aber durch Kubernetes als Dienst zur Container-Virtualisierung verwendet werden. Um auch hier Ressourcen zu sparen, habe ich mich dafür entschieden, nicht das volle Kubernetes (auch k8s genannt) zu verwenden, sondern in Form von k3s auf eine besonders schlanke Version von Kubernetes zu setzen.
Damit ich meine Container und Dienste leichter verwalten kann soll außerdem noch das Kubernetes Dashboard auf dem Raspberry Pi installiert werden.
Da nun also geklärt wäre, was passieren soll, kann’s nun endlich mit dem Basteln losgehen.
Alpine Linux herunterladen und die MicroSD-Karte vorbereiten
Als erstes benötige ich die für den RasPi angepasste Version von Alpine Linux. Für den Raspberry Pi 3 B lade ich die Archivdatei für aarch64 auf der Downloads-Seite von Alpine Linux herunter und zusätzlich auch direkt die Datei mit der SHA256-Prüfsumme der Archivdatei, damit ich verifizieren kann, dass das Archiv nicht beschädigt ist.

Nach dem Download der beiden Dateien prüfe ich mithilfe der SHA256-Summe, ob die Datei korrekt heruntergeladen wurde. Unter macOS führe ich dazu den Befehl shasum -c alpine-rpi-3.13.2-aarch64.tar.gz.sha256 aus. Da die errechnete Prüfsumme mit der aus der Prüfsummendatei übereinstimmt, ist die Datei unbeschädigt und es kann mit dem Erstellen des Installationsdatenträgers weitergehen.
Mit Hilfe des Festplattendienstprogramms überschreibe ich die MicroSD-Karte mit einer neuen MBR-Partitionstabelle, die nur eine einzelne Partition enthält. Die Partition formatiere ich mit FAT32 und weise ihr den gesamten verfügbaren Speicherplatz zu. Die MicroSD-Karte kann man natürlich auch mit einem anderen Programm formatieren; unter Linux bietet sich zum Beispiel GParted dafür an. Wichtig ist nur, dass keine GPT-Partitionstabelle, sondern eine MBR-Tabelle verwendet wird und, dass die Partition mit FAT32 formatiert wird. Der Raspberry Pi kann nur von einer FAT32-Partition booten. Andere Dateisysteme lassen sich erst nach dem Booten einbinden.
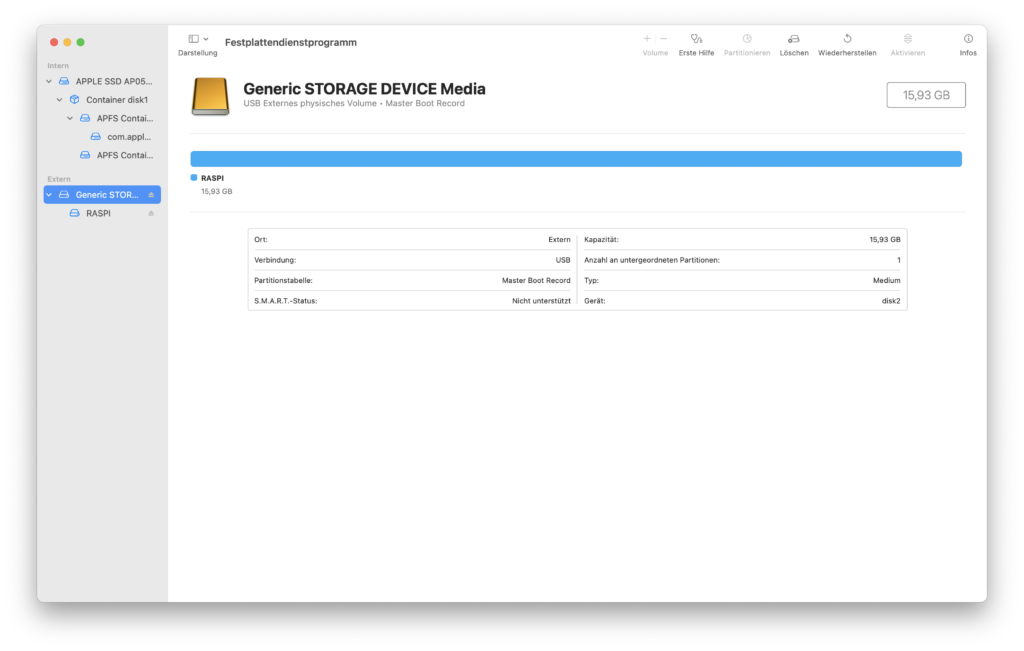
Nachdem die neue Partition formatiert und automatisch in das laufende System eingebunden wurde, kann ich nun die Systemdateien von Alpine Linux auf die Partition kopieren. Dazu öffne ich eine Terminal, navigiere mit cd zur eingebundenen Partition (hier /Volumes/RASPI) und entpacke die Archivdatei mit tar -xzf alpine-rpi-3.13.2-aarch64.tar.gz. Danach kann ich das Terminal schließen und die MicroSD-Karte über den Dateibrowser sicher auswerfen.
Die so vorbereitete MicroSD-Karte packe ich nun in den Slot am Raspberry Pi und schließe zusätzlich noch einen Bildschirm, eine Tastatur, ein Netzwerkkabel und ein USB-Netzteil an. Der RasPi bootet nun Alpine Linux als Live-System von der Karte. Damit ich das System einrichten und Daten über einen Neustart hinweg speichern kann, muss ich Alpine Linux jetzt noch im sogenannten sys-Modus auf der Karte installieren. Da ich beim Installieren des Systems keine Bildschirmfotos aufnehmen kann, hab ich die Installation noch einmal in einer virtuellen Maschine nachgestellt.
Alpine Linux im sys-Modus installieren
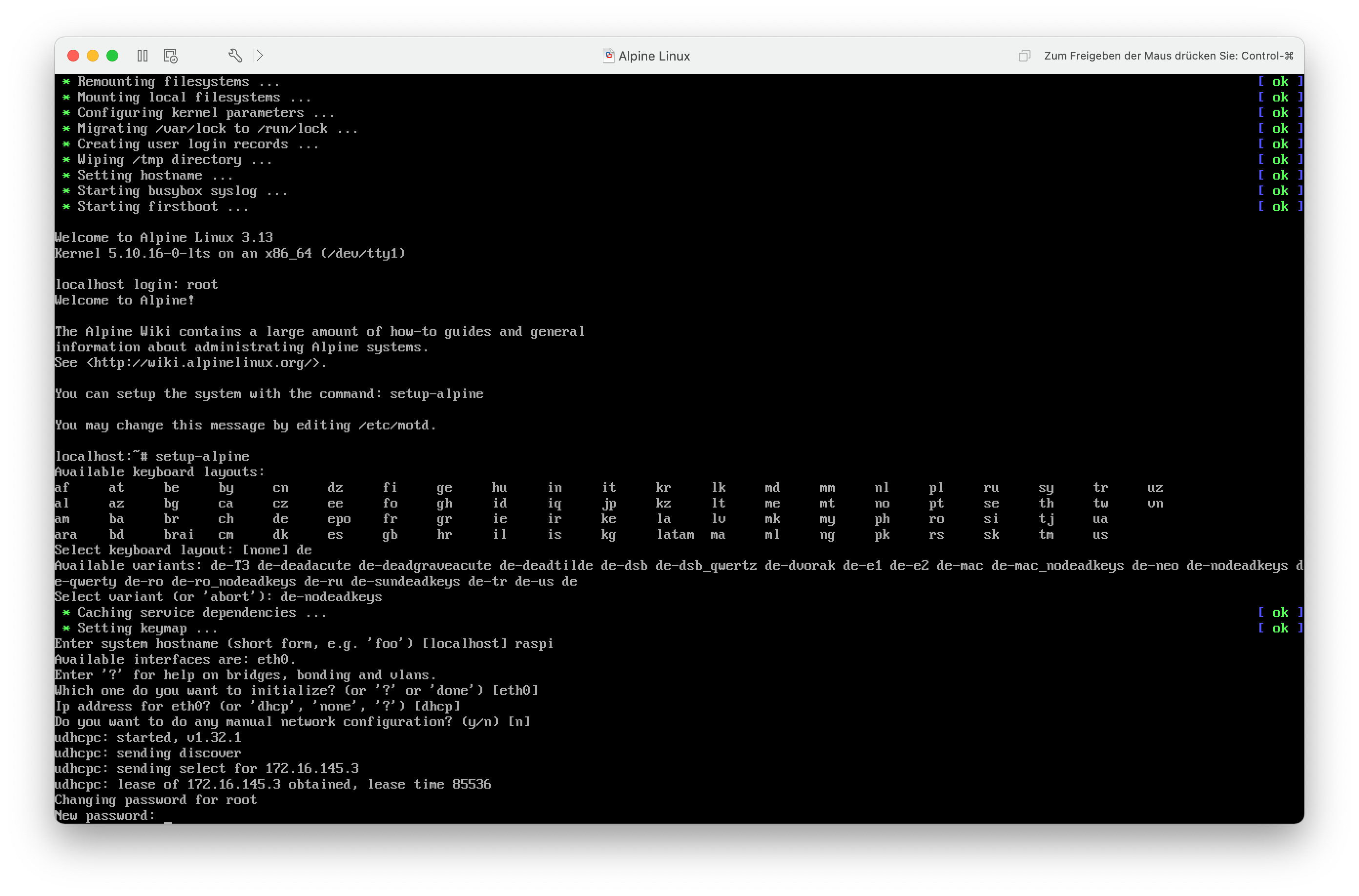
Als erstes muss ich mich im Live-System anmelden. Standardmäßig kann ich mich mit dem Benutzernamen root ohne Passwort einloggen. Danach starte ich mit setup-alpine das Konfigurationsprogramm für die grundlegenden Systemeinstellungen. Die entsprechenden Schritte habe ich für die Galerie am Ende dieses Kapitels in einer VM nochmal nachgestellt.
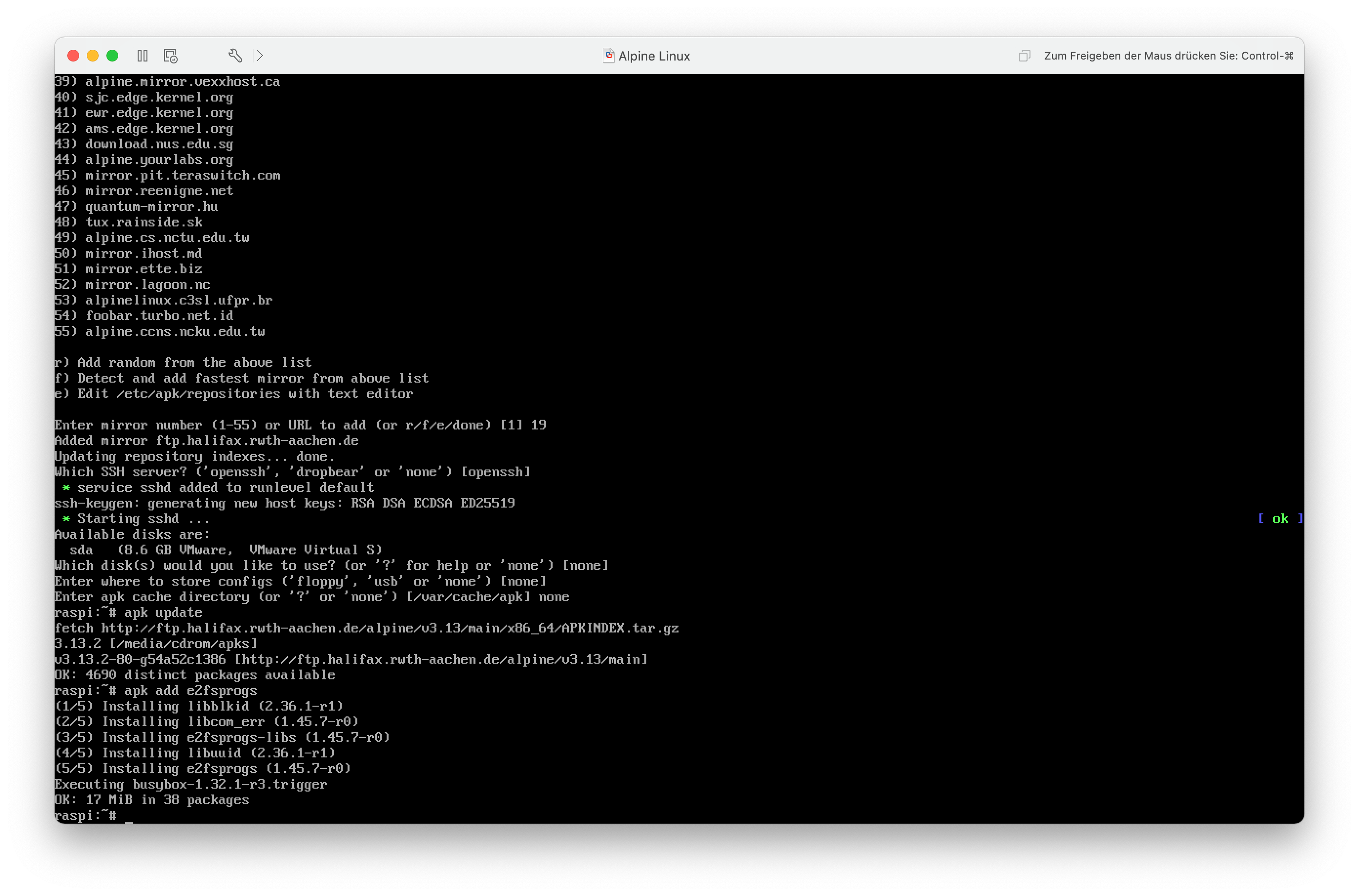
Nachdem alles konfiguriert ist, aktualisiere ich mit apk update den Paketindex, so dass nun Pakete vom eben ausgewählten Mirror installiert werden können. Damit bei der Installation auf der MicroSD-Karte eine Systempartition mit ext4 erstellt werden kann, müssen noch die Dateisytemtools für die ext-Dateisysteme installiert werden. Dazu führe ich apk add e2fsprogs aus.
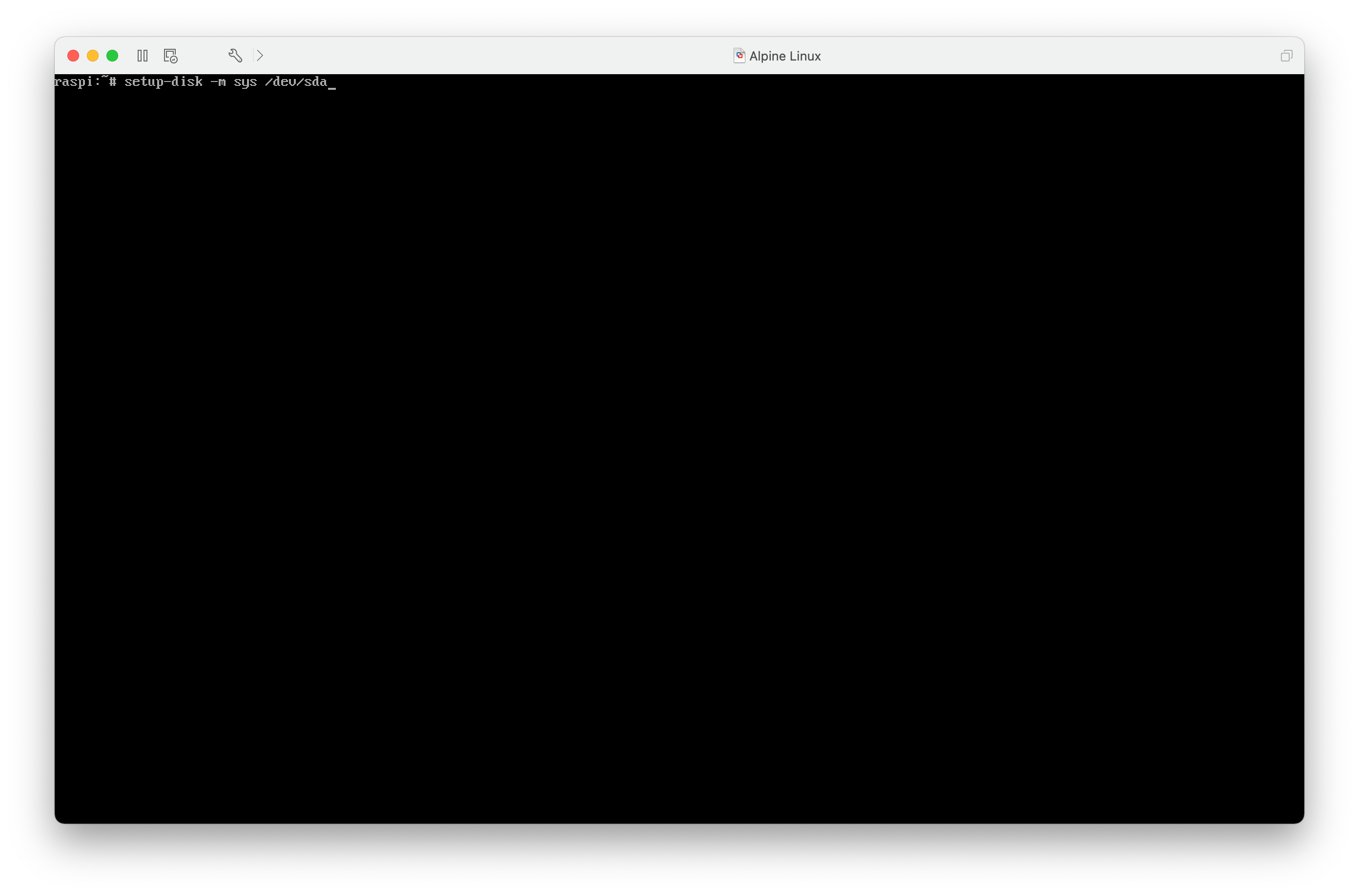
Nun kann ich Alpine Linux inklusive der aktuellen Konfiguration mit setup-disk -m sys /dev/mmcblk0 im sys-Modus auf der Karte installieren. Nach einem Neustart läuft nun Alpine Linux wie jedes andere Linux auf dem Raspberry Pi und Änderungen am System überleben auch einen Neustart. Nun kann ich mit der Konfiguration fortfahren und die Installation von Kubernetes angehen.
Nachdem ich mich mit dem Benutzernamen root und leerem Passwort angemeldet habe, starte ich das Konfigurationsprogramm mit setup-alpine. 
Als erstes muss ich das Tastaturlayout festlegen. Normalerweise ist das de-nodeadkeys. 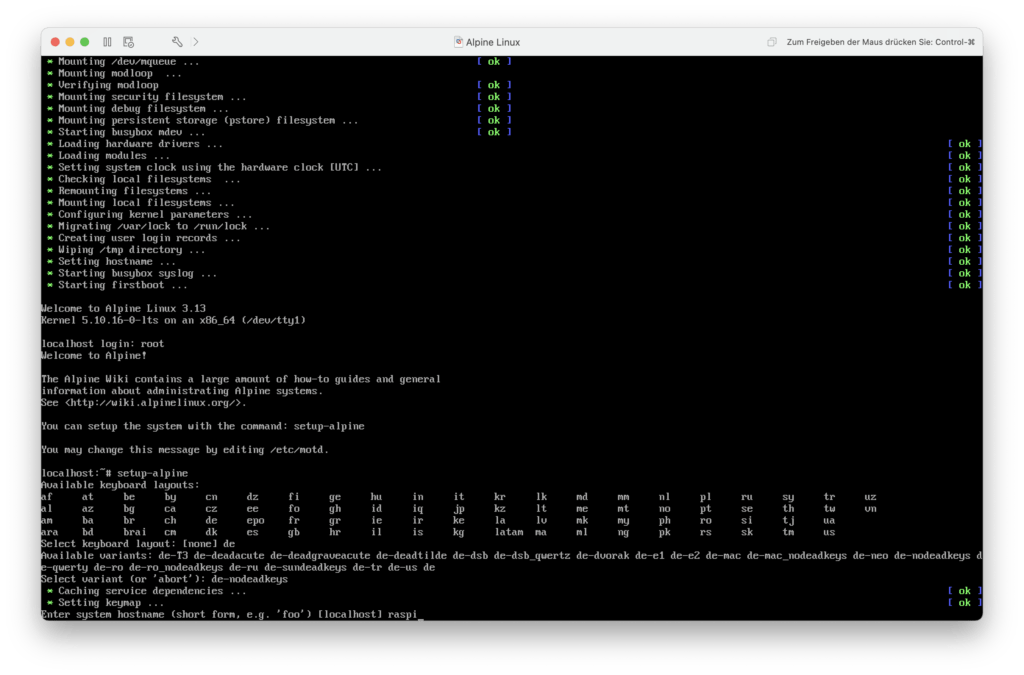
Als nächstes muss ein Hostname festgelegt werden. Ich möchte den Raspberry Pi später unter dem Namen raspi erreichen. 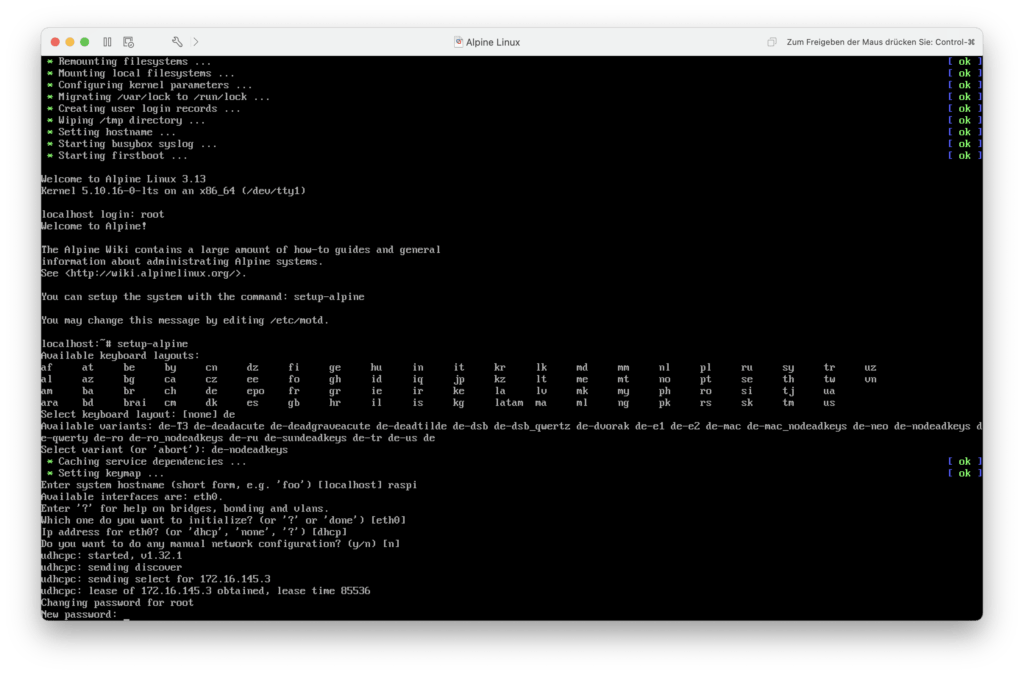
Danach konfiguriere ich den Kabel-Netzwerkanschluss mit DHCP. Den W-LAN-Anschluss spar ich mir erstmal. 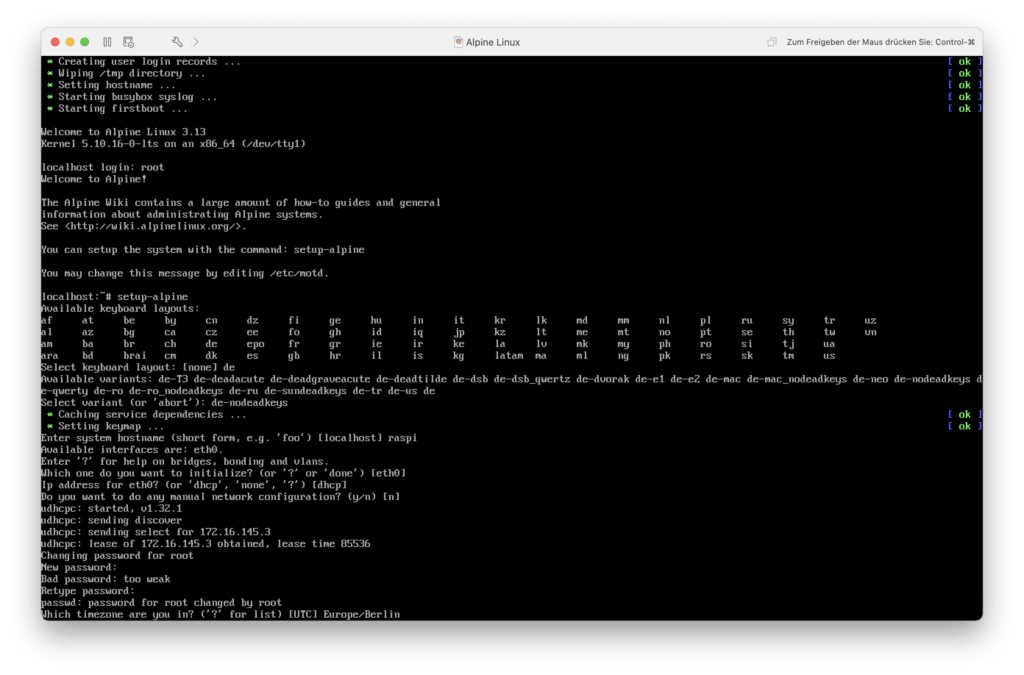
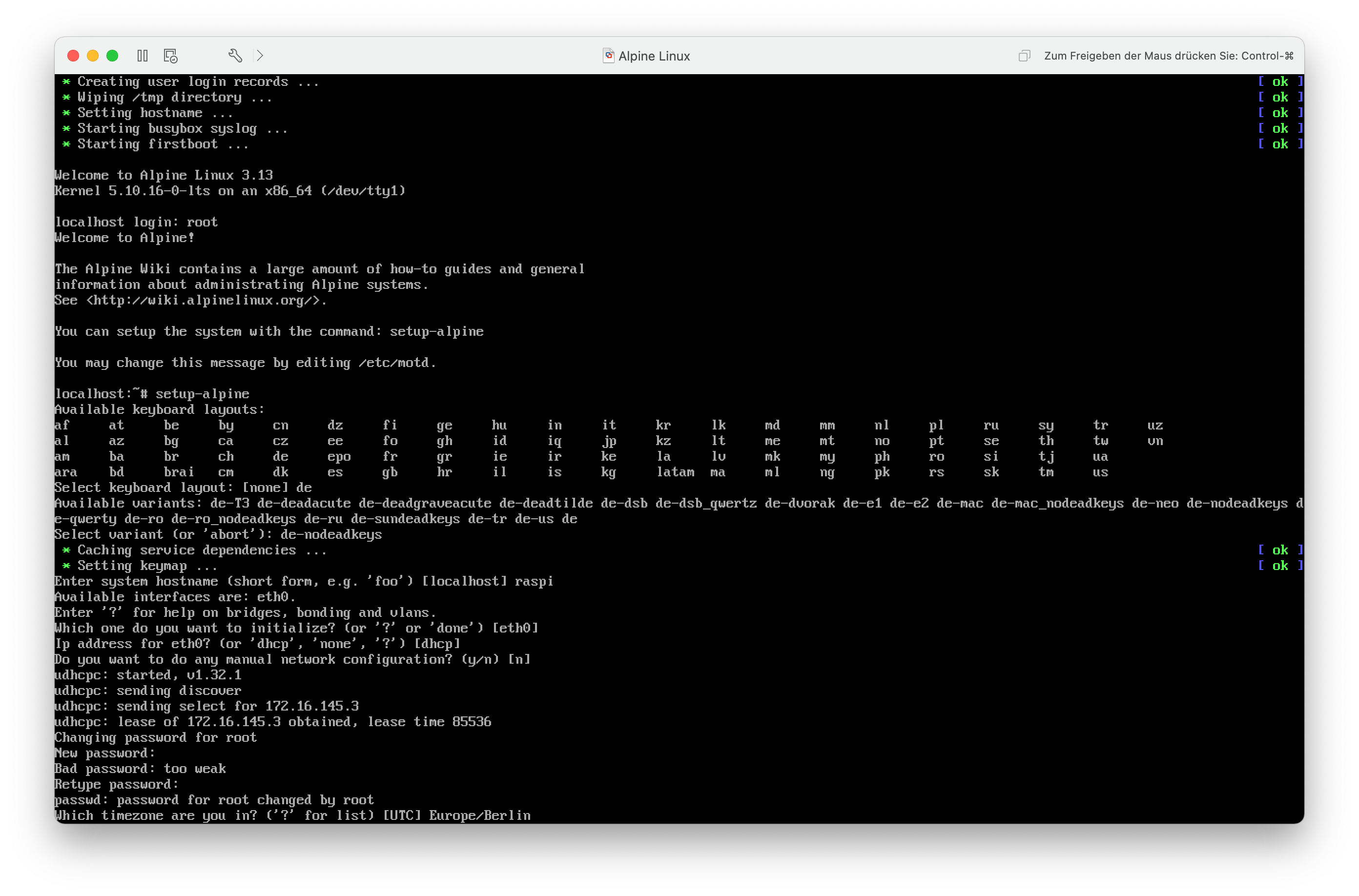
Als nächstes muss ich ein Benutzerpasswort für den root-Benutzeraccount anlegen und die Zeitzone festlegen (Europe/Berlin). 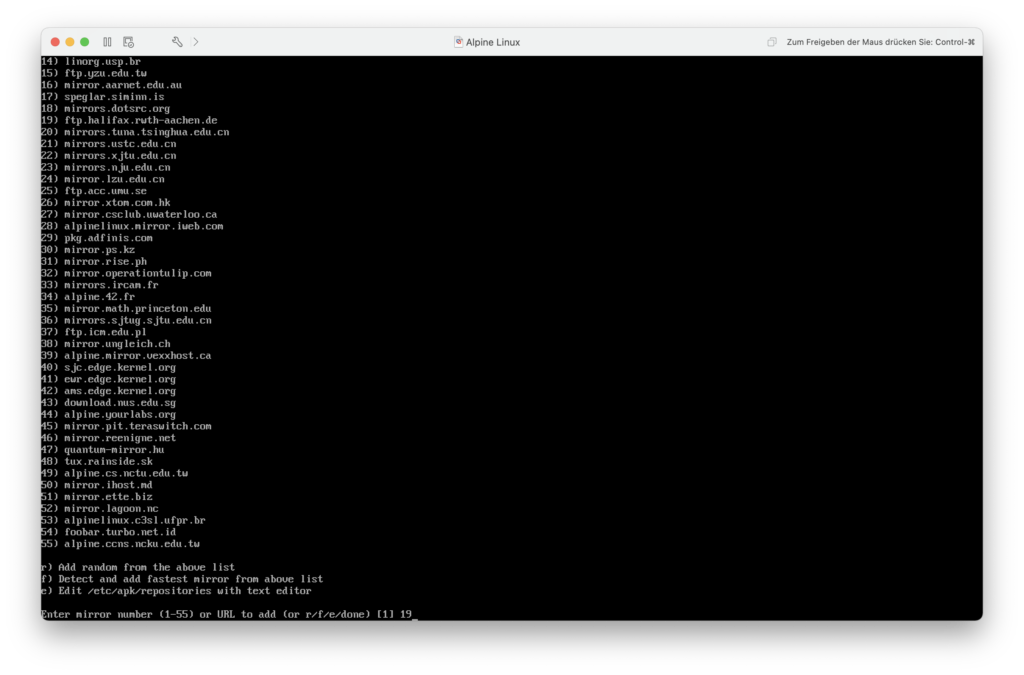
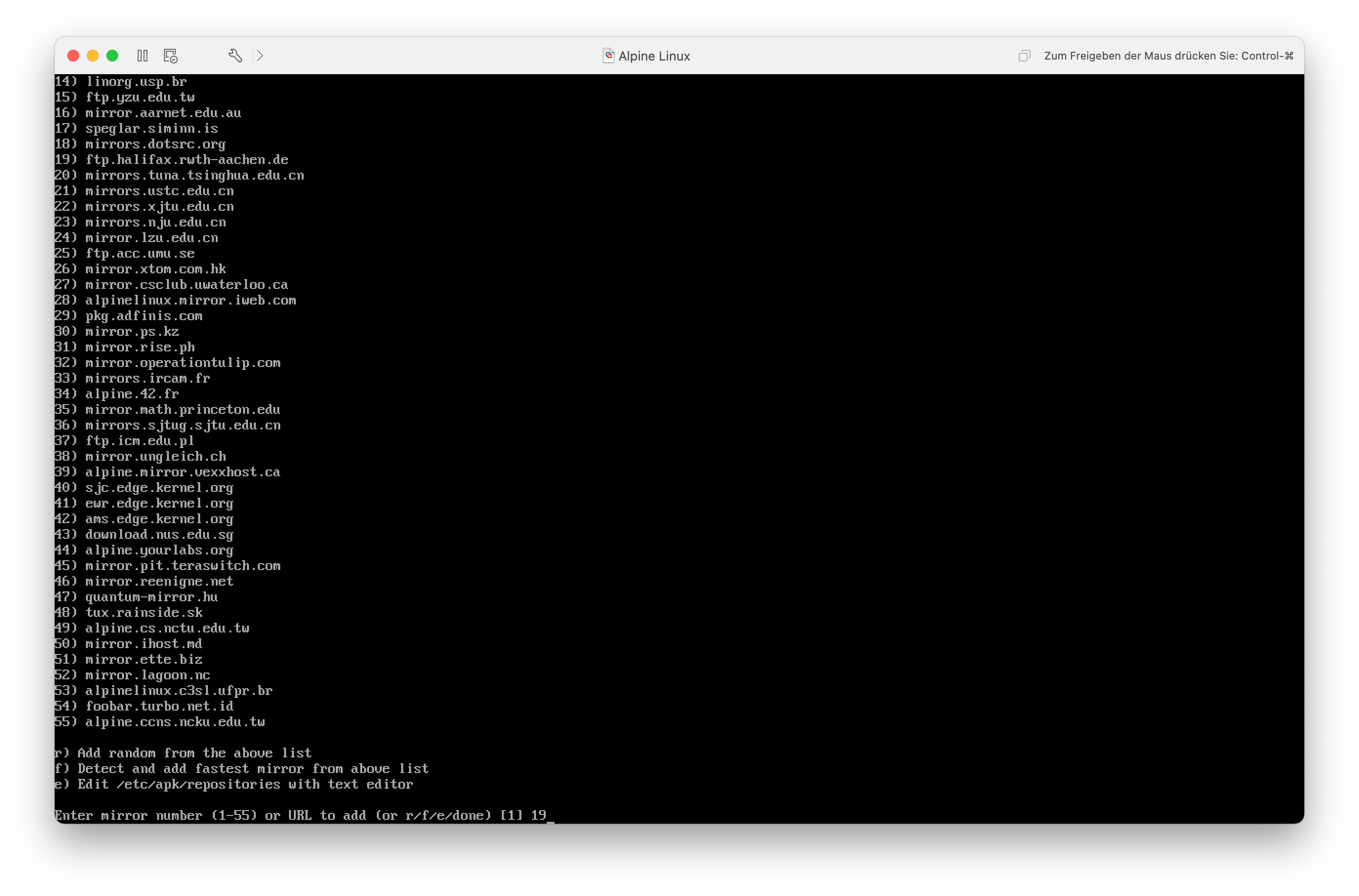
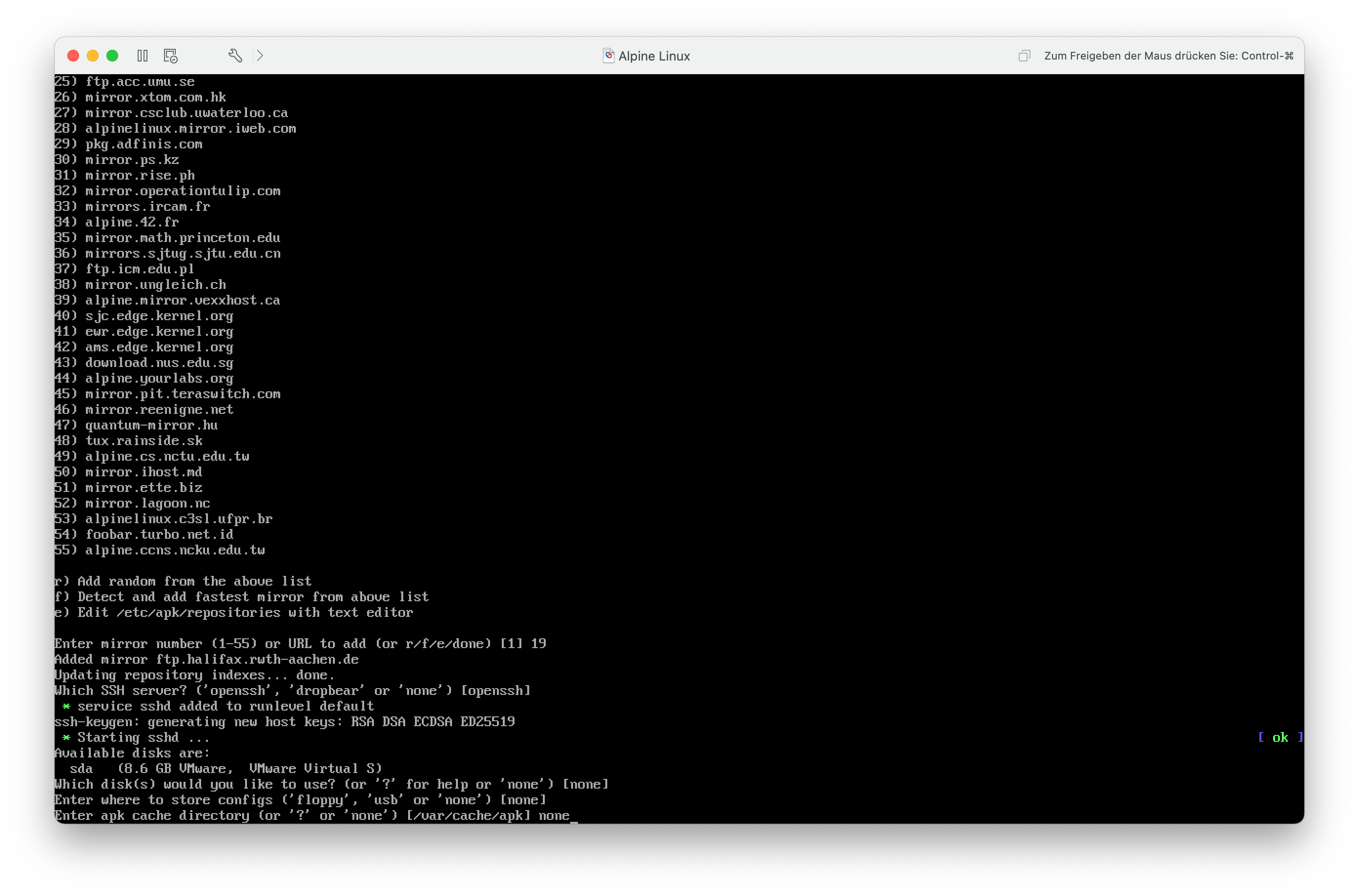
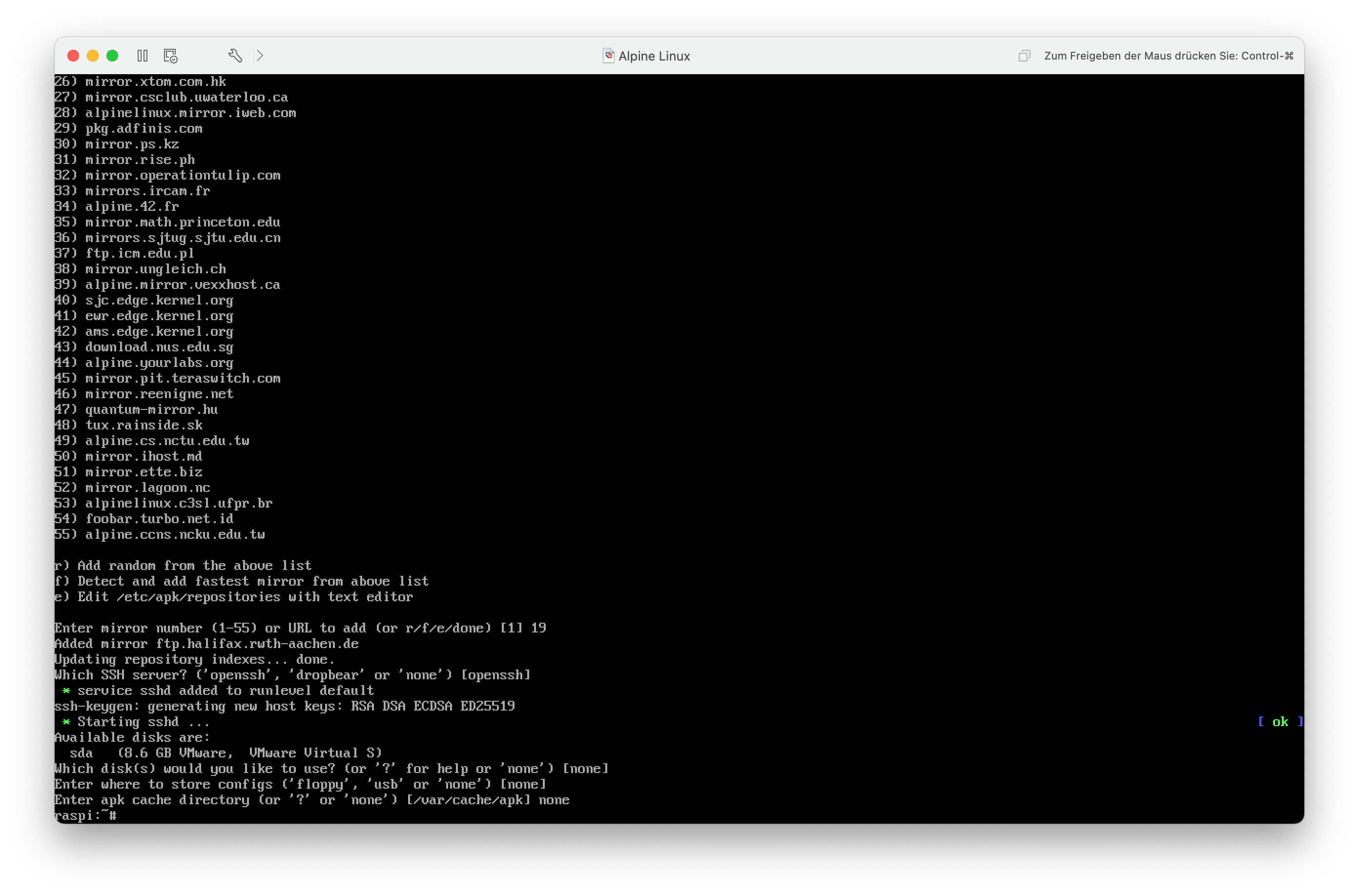
Nun kann ich einen Mirror für die Installation von Softwarepaketen festlegen. Ich entscheide mich für den Mirror der RWTH Aachen, da der in der Nähe gehostet wird. 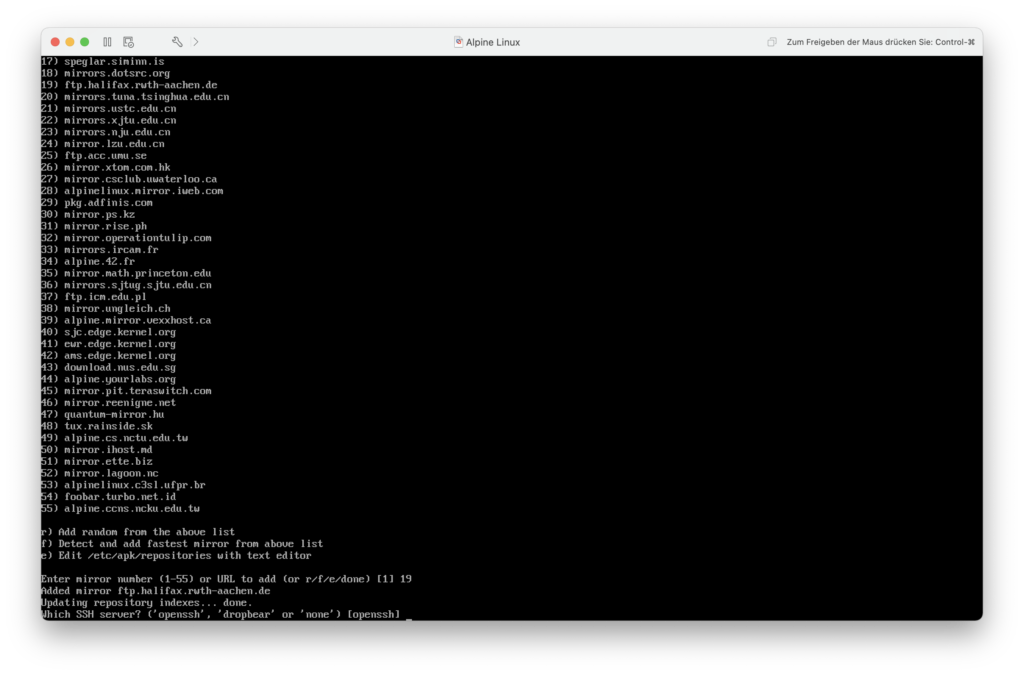
Nachdem der Mirror festgelegt und der Paketindex aktualisiert wurde, lege ich den zu verwendenden SSH-Server fest. Ich bleibe hier einfach beim Standard – OpenSSH. 
Da ich das System nur vorkonfigurieren will und die Partitionen der MicroSD-Karte gleich ohnehin überschrieben werden, wähle ich keinen Config-Ordner und keinen APK Cache aus. 
Damit ist das System nun vorkonfiguriert und muss nur noch auf die Karte installiert werden. 
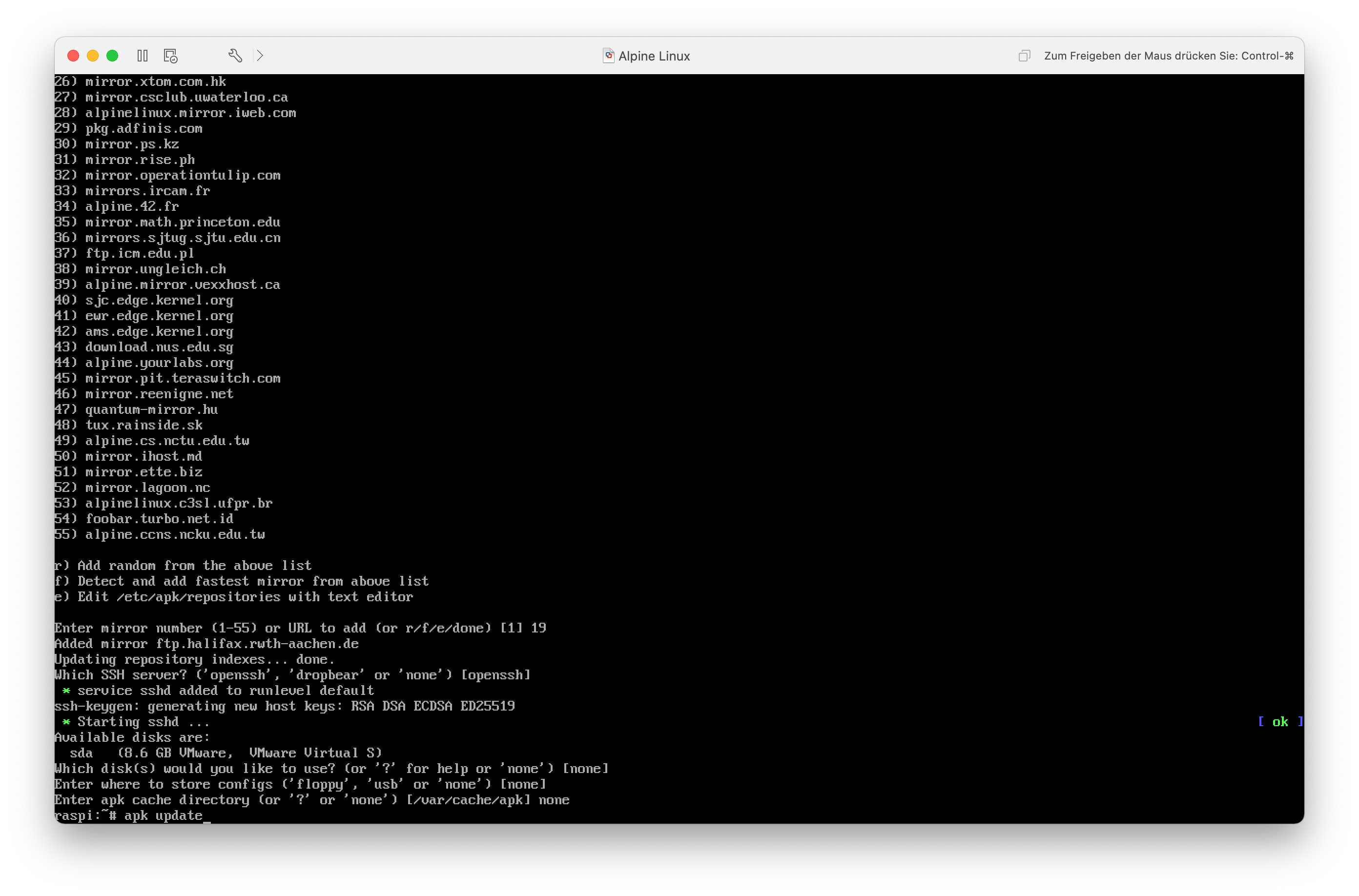
Zunächst aktualisiere ich erst mal den Paketindex. 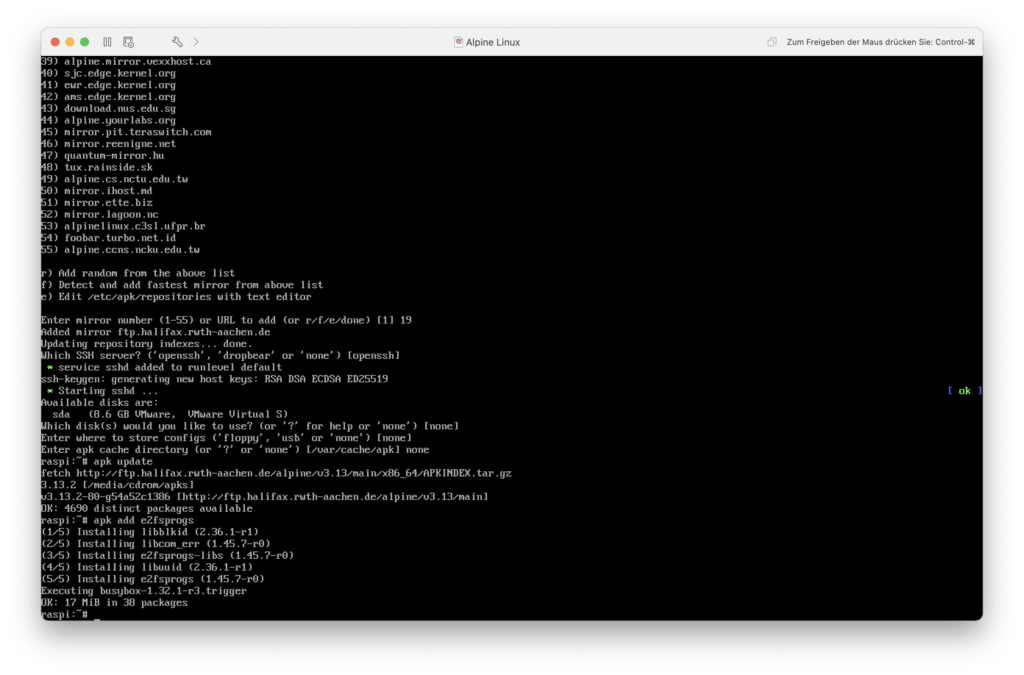
Danach installiere ich das Paket mit den Programmen für die Ext-Dateisysteme nach, damit ich für die Systempartition Ext4 verwenden kann. 
Nun kann ich das vorkonfigurierte Alpine Linux auf der MicroSD-Karte installieren. Da das Live-System komplett im Arbeitsspeicher liegt, kann die Karte einfach überschrieben werden.
Auf dem Raspberry Pi heißt der Pfad nicht /dev/sda, sondern /dev/mmcblk0.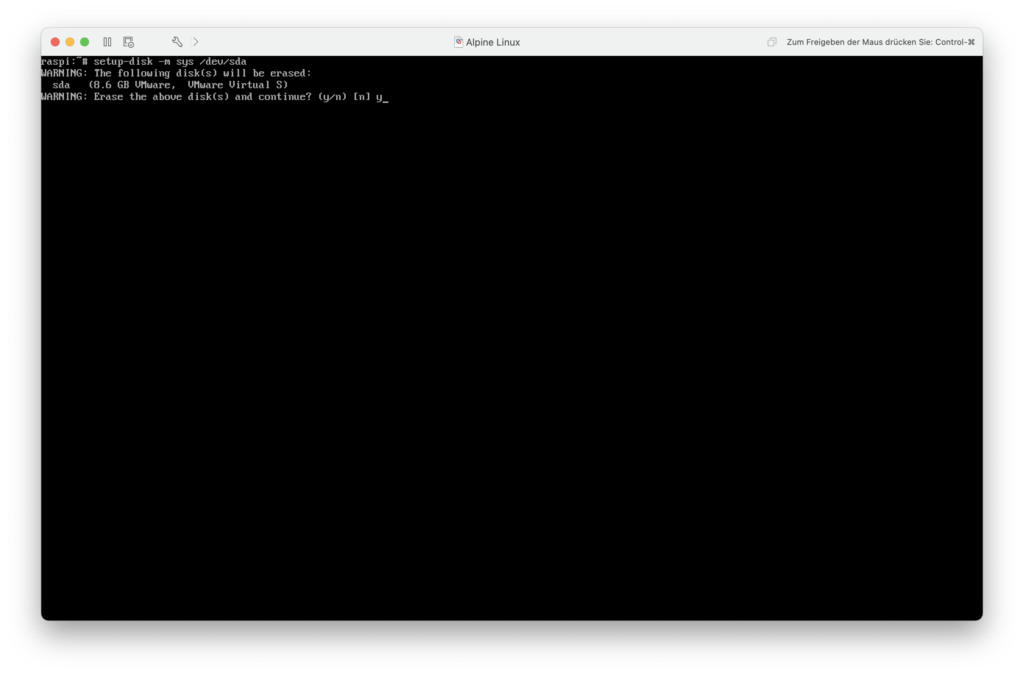
Nachdem ich das Überschreiben der Karte (bzw. der Festplatte hier im Beispiel in der VM) bestätigt habe… 
…wird Alpine Linux im sys-Modus auf der Karte installiert. Dabei werden eine FAT32-Bootpartition und eine Ext4-Systempartition zum persistenten Speichern von Dateien und Programmen erstellt.




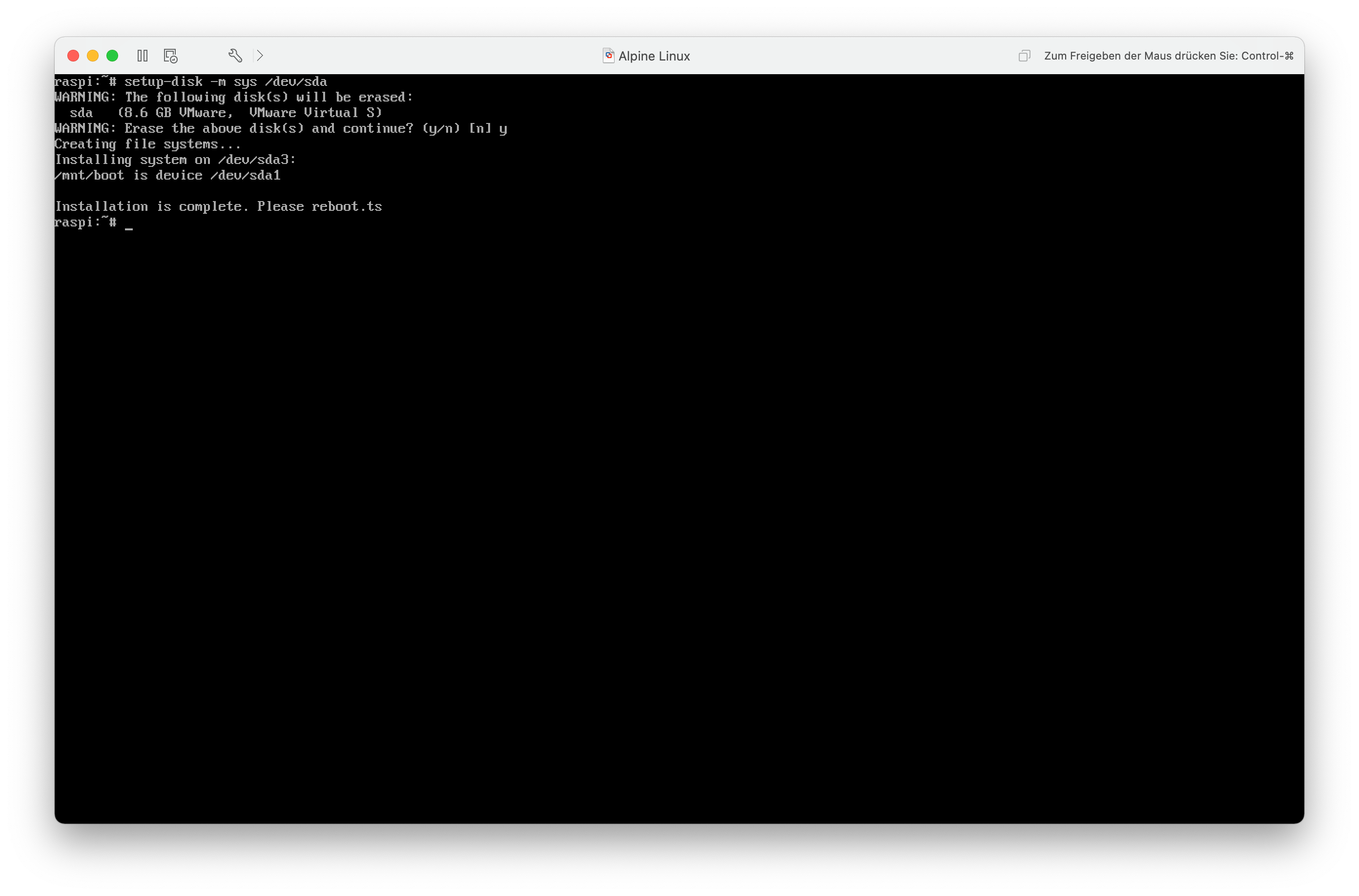
Benutzer anlegen
Zunächst lege ich einen neuen Benutzer mit Adminrechten an, da ich im Anschluss den SSH-Zugang aktivieren werde und der Root-Account aus Sicherheitsgründen nicht über SSH zugänglich sein soll. Mit adduser -h /home/ahahn94 -s /bin/ash ahahn94 erstelle ich ein neues Benutzerkonto für mich und lege den Pfad für meinen Benutzerordner und die Standard-Shell für meine Terminalsitzungen fest. Dabei lege ich auch das Passwort für mein neues Konto fest.
Anschließend muss ich zunächst mit apk add sudo das Programm sudo zum Ausführen von Programmen mit Administratorrechten nachinstallieren. Mit echo '%wheel ALL=(ALL) ALL' > /etc/sudoers.d/wheel gebe ich der Gruppe wheel (das ist die Standard-Admingruppe unter Linux) Adminrechte unter sudo.
Abschließend füge ich mit adduser ahahn94 wheel meinen Benutzeraccount zur Admingruppe hinzu. Nach einem Neustart logge ich mich nun mit meinem eigenen Konto ein und verwende sudo, um Programme mit Adminrechten auszuführen.
SSH einrichten
Nach dem Einrichten des Kontos kann nun der SSH-Zugang aktiviert werden:
Als erstes installiere ich den Editor Nano nach, damit ich mich nicht mit VI herumärgern muss, mit sudo apk add nano. Danach entferne ich mit sudo nano /etc/ssh/sshd_config das Kommentar-Zeichen (#) vor der Zeile PasswordAuthentication yes und starte den SSH-Dienst mit sudo service sshd restart neu. Nun kann ich mich von meinem MacBook aus mit meinem Konto und Passwort anmelden.
Um die Sicherheit zusätzlich zu erhöhen, hinterlege ich meinen öffentlichen RSA-Schlüssel in meinem Benutzerverzeichnis auf dem Raspberry Pi, indem ich am MacBook ein Terminal öffne und ssh-copy-id raspi ausführe. Danach deaktiviere ich die Anmeldung per Passwort, indem ich auf dem RasPi das eben entfernte Kommentarzeichen wieder einfüge und den SSH-Dienst erneut neustarte. Damit kann ich mich nun nur noch über meinen privaten Schlüssel anmelden, der deutlich sicherer ist als mein Benutzerkennwort.
k3s installieren
Nachdem jetzt alle Vorarbeiten erledigt sind und ich den Raspberry Pi ohne Bildschirm und Tastatur laufen lassen kann (dafür habe ich ja SSH eingerichtet), kann ich nun endlich Kubernetes installieren. Dazu verbinde ich mich über die Terminal-App am MacBook via SSH mit dem RasPi.
Als erstes muss ich cURL mit sudo apk add curl nachinstallieren. Danach lade ich das Installationsskript für k3s (eine leichtgewichtigere Variante von Kubernetes) herunter und speichere es in meinem Benutzerverzeichnis. Dazu führe ich den Befehl curl -sfL https://get.k3s.io > install-k3s.sh aus. Damit ich das Skript ausführen kann, muss ich erst noch mit chmod +x install-k3s.sh die Datei ausführbar machen. Danach kann ich mit sudo ./install-k3s.sh k3s installieren.
Nun ist der Kubernetes-Dienst installiert, aber er kann noch nicht gestartet werden. Dazu müssen erst noch mit echo 'cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory' >> /boot/cmdline.txt ein paar Dinge für die Containerisierung aktiviert werden. Nach einem Neustart startet der Kubernetes-Dienst nun automatisch und läuft.
Kubernetes Dashboard installieren
Zum Schluss installiere ich nun noch das Kubernetes Dashboard, das mir die Verwaltung und Überwachung von Kubernetes vereinfacht. Dazu muss ich zunächst zwei Umgebungsvariablen setzen:
GITHUB_URL=https://github.com/kubernetes/dashboard/releases
VERSION_KUBE_DASHBOARD=$(curl -w '%{url_effective}' -I -L -s -S ${GITHUB_URL}/latest -o /dev/null | sed -e 's|.*/||')Nun kann ich die Kubernetes-Definitionsdatei für die aktuelle Version des Dashboards mit curl https://raw.githubusercontent.com/kubernetes/dashboard/${VERSION_KUBE_DASHBOARD}/aio/deploy/recommended.yaml > dashboard.yaml herunterladen. Mit sudo k3s kubectl create -f dashboard.yaml erstelle ich nun aus der Definitionsdatei einen neuen Service, der das Dashboard enthält.
Anschließend muss ich noch den Adminbenutzer für das Dashboard anlegen. Dazu muss ich zwei YAML-Dateien für die Benutzer- und Rollen-Konfiguration anlegen. Dazu verwende ich wieder Nano.
nano dashboard.admin-user.yml
apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard
nano dashboard.admin-user-role.yml
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard
Anschließen lade ich die Konfigurationsdateien in Kubernetes, damit der Benutzer und die Benutzerrolle erstellt werden. Dazu führe ich sudo k3s kubectl create -f dashboard.admin-user.yml -f dashboard.admin-user-role.yml aus.
Wie man an den Konfigurationen sehen kann liegt das Dashboard in einem eigenen Namespace, kubernetes-dashboard. Daher muss man bei vielen kubectl-Befehlen zusätzlich noch mit -n kubernetes-dashboard den Namespace mit angeben, damit die Dienste und Ressourcen gefunden werden. Wenn man stattdessen in allen Namespaces suchen möchte, verwendet man die Option -A. Durch Namespaces lassen sich mehrere Services und andere Kubernetes-Ressourcen (z.B. Benutzer, Rollen, etc.) gruppieren, was bei steigender Zahl an Diensten die Übersichtlichkeit deutlich verbessert. Der Kubernetes Dashboard Dienst lässt sich auch über kubernetes-dashboard/kubernetes-dashboard adressieren, d.h. der Namespace wird dem Namen der Ressource einfach mit einem Slash getrennt vorangestellt.
Damit ich mich im Dashboard anmelden kann benötige ich noch ein so genanntes Bearer Token, also eine Zeichenkette, die mich als Zugriffsberechtigten ausweist. Dazu führe ich sudo k3s kubectl -n kubernetes-dashboard describe secret admin-user-token | grep ^token aus und erhalte ein langen Schlüssel, den ich später kopieren und im Anmeldefenster des Dashboards einfügen muss.
Proxy für lokalen Zugriff auf das Dashboard starten (nur lokaler Zugriff)
Nun kann ich testen, ob das Dashboard bereitgestellt wird. Dazu führe ich sudo k3s kubectl proxy aus, wodurch der Port des Dashboards auf dem Raspberry Pi per localhost-Adresse zugänglich gemacht wird. Das Dashboard ist dabei von keinem anderen Rechner im Netzwerk aus zugänglich, sondern ausschließlich auf dem RasPi. Zum Testen genügt das allerdings erst einmal. Da der Proxy-Befehl solange läuft, bis man ihn mit Strg+C beendet, muss ich in meinem Terminal eine weitere SSH-Sitzung auf dem RasPi aufmachen. Dort kann ich nun mit curl http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/ testen, ob die Loginseite des Dashboards geladen wird oder ob stattdessen eine Fehlermeldungsseite angezeigt wird. Obwohl die geladene Seite als HTML-Code angezeigt wird, lässt sich recht gut erkennen, ob die Dashboard-Anmeldeseite geladen wurde. Da das bei mir der Fall ist, kann ich nun damit weitermachen, das Dashboard auch auf anderen Rechnern im Netzwerk verfügbar zu machen. Dazu schließe ich allerdings erst noch die zweite SSH-Sitzung und beende mit Strg + C den Proxy.
Remote Zugriff auf das Dashboard ermöglichen
Damit ich auch von meinem MacBook aus auf das Kubernetes Dashboard zugreifen kann, muss ich dessen Service noch ein bisschen anpassen. Dazu öffne ich über sudo k3s kubectl edit service/kubernetes-dashboard -n kubernetes-dashboard einen Texteditor (standardmäßig leider VI) mit der Konfigurationsdatei des Dienstes. Dort trage ich einen NodePort zwischen 30000 und 32767 ein (das ist der von Kubernetes vorgegebenen Portnummernbereich) und ändere den Typ auf NodePort. Ich habe mich hier für die Portnummer 30443 entschieden, weil das Dashboard Service-intern auf Port 443 läuft. Das sieht dann in etwa so aus:
spec: ... port: - nodePort: 30443 ... type: NodePort
Nachdem ich diese Änderungen vorgenommen habe, drücke ich ESC, tippe :wq ein und bestätige mit Enter, um die Änderungen zu speichern und den Editor zu schließen. Die Änderungen an der Konfiguration werden sofort angewandt, so dass ich nun im Browser auf dem MacBook unter https://raspi:30442 das Dashboard erreiche. Da das Dashboard Service-intern auf Port 443 (HTTPS) läuft, muss ich hier natürlich auch https:// verwenden und nicht http://.
Da das Dashboard kein verifizierbares Zertifikat verwendet, erhalte ich im Browser eine Sicherheitswarnmeldung. Bei Google Chrome auf macOS reicht es leider nicht, einfach auf Erweitert zu klicken und dort das Laden der Webseite zu bestätigen. Stattdessen muss ich nach dem Klicken auf Erweitert den Satz “thisisunsafe” eingeben. Da dafür kein Textfeld vorgesehen ist, muss ich den Satz ohne optisches Feedback eingeben. Danach lädt die Webseite dann allerdings und in Zukunft wird die Seite auch trotz Zertifikatfehler sofort geladen. Als ich das erste Mal feststellen musste, das der Bestätigen-Button unter macOS fehlt, musste ich erst mal einige Minuten recherchieren, wie ich denn nun überhaupt die Seite geladen bekomme. Das war natürlich sehr nervig.
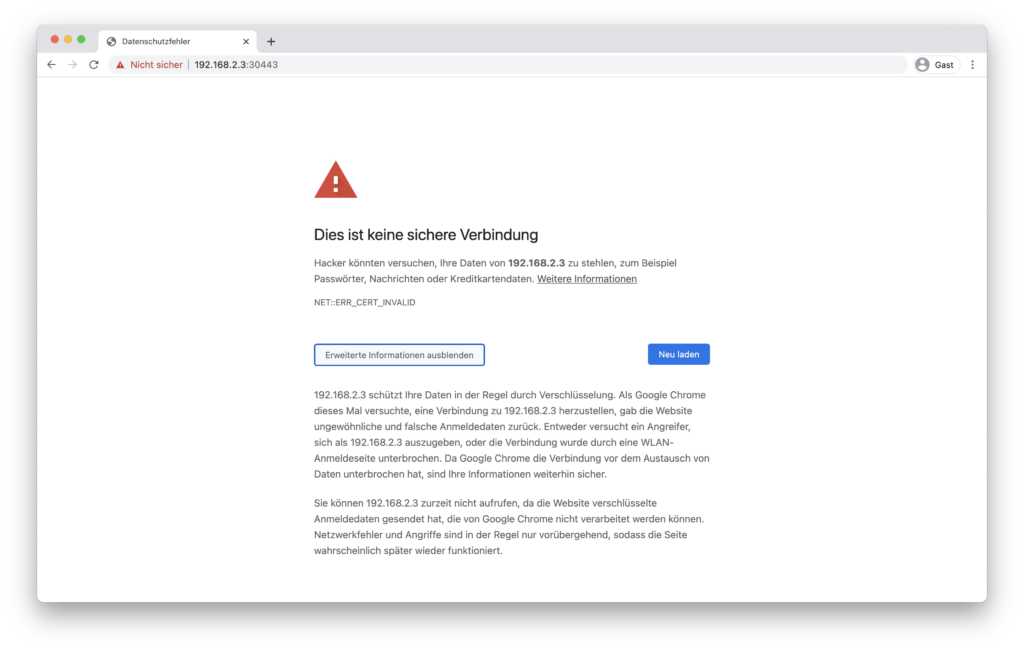
Login im Dashboard
Nachdem nun das Dashboard auch von anderen Rechnern im Netzwerk aus zugänglich ist, kann ich mich nun zum ersten Mal dort einloggen. Dazu benötige ich das Bearer Token von vorhin. Nochmal zur Erinnerung: sudo k3s kubectl -n kubernetes-dashboard describe secret admin-user-token | grep ^token. Auf der Loginseite wähle ich oben Token aus und füge dann unten das kopierte Token ein. Nach einem Klick auf Anmelden wird mir nun das Kubernetes Dashboard angezeigt.
Allerdings ist das Dashboard völlig leer. Das liegt daran, dass ich keine Dienste im default-Namespace angelegt habe. Oben neben der Suchleiste befindet sich eine Schaltfläche zum Auswählen des Namespace. Nachdem ich dort den kubernetes-dashboard-Namespace ausgewählt habe füllt sich das Dashboard mit Infos.
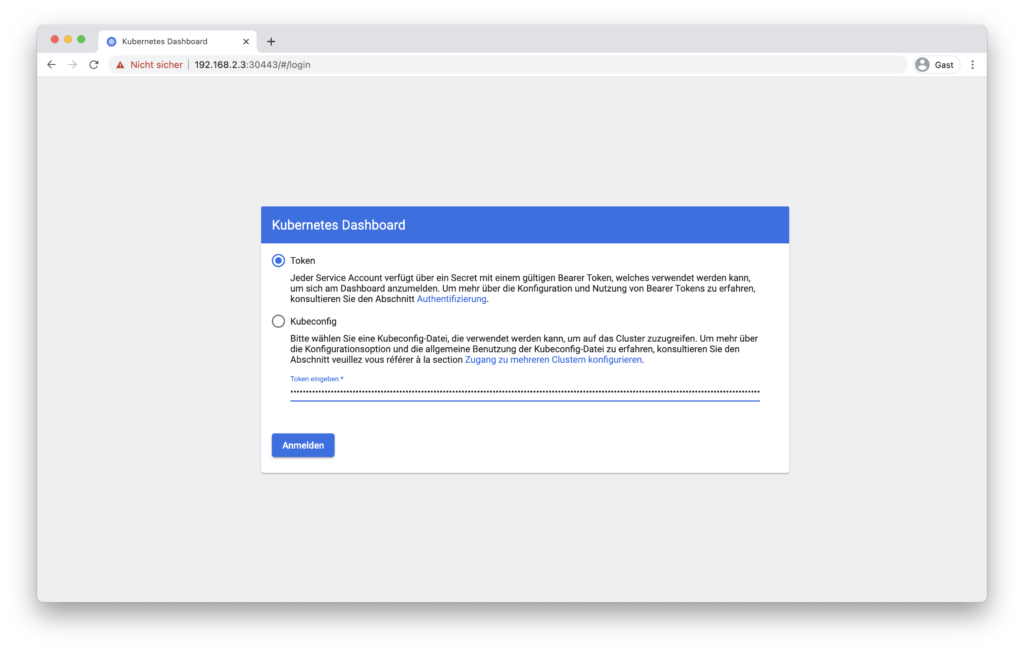
Zum Anmelden benötige ich das Bearer Token. 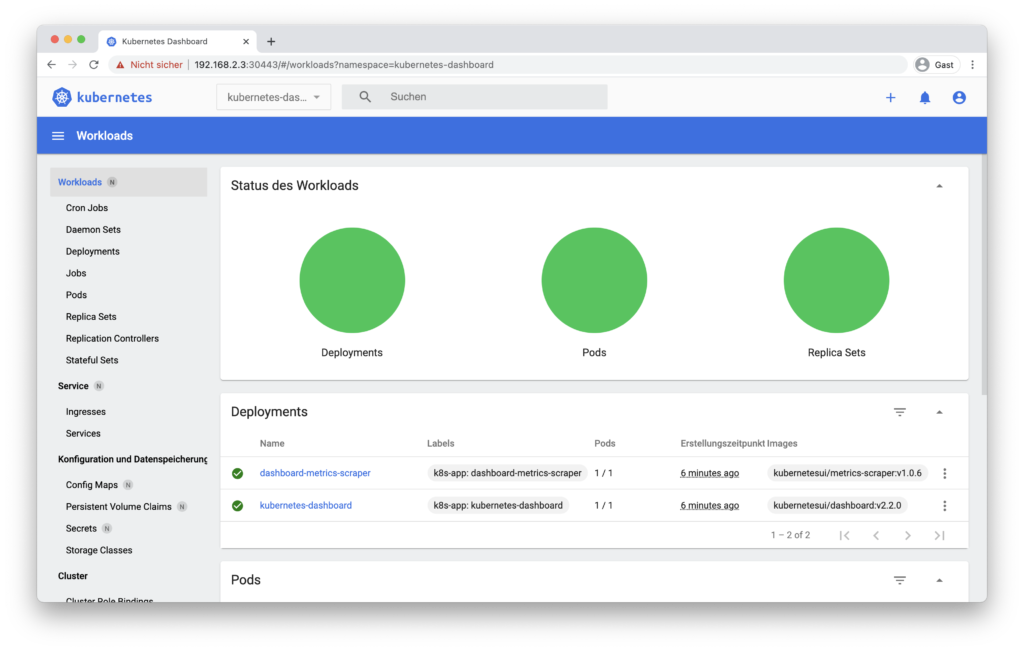
Nachdem ich neben der Suchleiste den Namespace zu kubernetes-dashboard gewechselt habe, wird das Dashboard mit Daten gefüllt.
Ausblick
Da Kubernetes nun läuft und auch das Dashboard von meinem Notebook aus zugänglich ist, können die ersten Uni-Projekte kommen. Zum Erstellen neuer Container kann ich per SSH auf dem Server kubectl ausführen und so meine Web- und Datenbankserver erstellen. Oder ich könnte kubectl auf dem MacBook nachinstallieren und es sogar über ein Plugin in meiner Programmierumgebung verwenden.
Momentan überlege ich noch, welche anderen Container ich auf dem RasPi ausführen möchte. Ich könnte zum Beispiel mit Hilfe eines Gitea-Containers einen kleinen Git-Server zur Verwaltung meiner Projekte betreiben. Oder ich könnte meine Projekte um ein bisschen Continuous Integration erweitern, so dass z.B. mit dem Aktualisieren des Git-Repos eines Projekts automatisch der Webserver des Projekts neu erstellt wird, so dass ich dort immer die aktuelle Version drin habe. Mal schauen, wofür ich in den nächsten Wochen und Monaten noch einen Bedarf sehe. Wenn ich die Muße dazu finde, werde ich dann hier mit einem weiteren Blogpost anschließen.
Bis dahin bin ich erst mal gespannt, was die neuen Vorlesungen so bringen und beschäftige mich ausgiebig mit meiner neuen Akustikgitarre und dem schönen Wetter 😉





1 comments On Containern für Anfänger – Kubernetes und Alpine Linux auf dem Raspberry Pi
Hey André,
Toller Beitrag! Danke dir dafür.
Viele Grüße, Lukas